算法之LFU缓存算法
目录
警告
本文最后更新于 2022-11-18,文中内容可能已过时。
LFU(Least Frequently Used)最近最少使用算法。它是基于“如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小”的思路。
举个例子,缓存空间大小为3:
- put(1,“a”)
- put(2,“b”)
- get(1)
- get(2)
- put(3,“c”)
- put(4,“d”) // 此时LFU应该淘汰(3,“c”)
基于链表的设计
- 缓存需要存储key-value对.显然,对于key-value对的存储使用map是很高效的。时间复杂度可以达到O(1)级别。
- 访问次数存储
- 假设使用数组存储访问次数:
- 那么插入数据时,复杂度是O(1),次数直接插入数组末尾
- 访问时,复杂度是O(1).
- 淘汰时,复杂度是O(n),遍历淘汰最小值。
- 假设使用有序数组存储访问次数:
- 那么插入数据时,复杂度是O(1),次数直接插入数组末尾
- 访问时,复杂度是O(logn).
- 淘汰时,复杂度是O(1),遍历淘汰最小值。
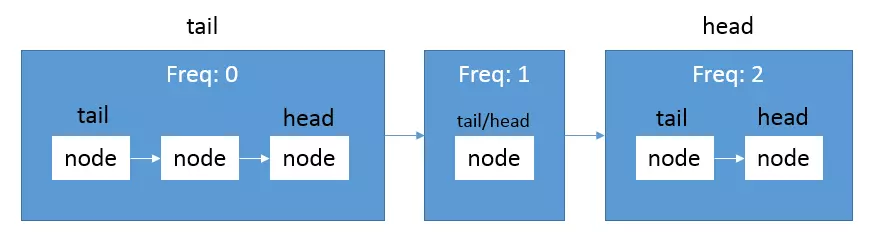
- 使用两层链表,外层链表的每个节点代表一组拥有同样访问次数的key,每个节点自身也是一个链表,内层链表确保上次访问时间最早的key位于内层链表的尾部。在这一数据结构下,插入、访问、移除的时间复杂度都是O(1)。
- 我们在插入key时判断外层链表尾部元素的freq(次数)是否为0,
- 如果是,将key插入该内层链表的头部,
- 如果否,生成一个只包含key的外层链表,插入到外层链表的尾部。
- 在访问key时,将该key移动到外层链表的下一个节点的头部。
- 在移除key时,只需要移除外层链表尾部元素的尾部元素.
public class LFUCacheUsingTwoWayLinkedList<K, V> {
/**
* 链表尾部的NodeQueue,指向访问次数最少的节点
*/
public CacheNodeQueue tail;
/**
* 容量
*/
public int capacity;
public HashMap<K, Pair<Integer,V>> getMap() {
HashMap<K, Pair<Integer,V>> hashMap = new HashMap<>();
map.forEach((x,y)->{
hashMap.put(x,Pair.of(y.currentLevelQueue().frequency,y.value));
});
return hashMap;
}
/**
* 存储key-value对的HashMap
*/
private HashMap<K, CacheNode<K,V>> map;
//构造方法
public LFUCacheUsingTwoWayLinkedList(int capacity) {
this.capacity = capacity;
map = new HashMap<K, CacheNode<K,V>>(capacity);
}
/**
* Node升级到下一个queue
* @param n
*/
private void moveNodeToNextLevelQueueHead(CacheNode n){
CacheNodeQueue current = n.currentLevelQueue();
int valueFrequency= current.frequency+1;
CacheNodeQueue nextLevel = current.high;
if(current.isHeadQueue()){
if(current.isSingleQueue()) {
// 单元素节点直接增加queue的frequency
current.frequency++;
}else {
//在下一级直接加上一个新节点
unlinkNode(n);
new CacheNodeQueue(current, null, n, n, valueFrequency);
}
}else {
if (current.high.frequency == valueFrequency) {
if(current.isSingleQueue()) {
unlinkNode(n);
nextLevel.addNodeToHead(n);
if(current.isTailQueue()){
tail = nextLevel;
nextLevel.low = null;
}else {
current.low.high = nextLevel;
nextLevel.low = current.low;
}
}else {
//下一级NodeQueue的访问次数与Node当前访问次数一样,
//把Node插入到下一级NodeQueue的头部
unlinkNode(n);
nextLevel.addNodeToHead(n);
}
}else if (current.high.frequency > valueFrequency) {
if(current.isSingleQueue()) {
if(current.isTailQueue()){
current.frequency++;
}else {
unlinkNode(n);
nextLevel = new CacheNodeQueue(current, current.high, n, n, valueFrequency);
current.low.high = nextLevel;
nextLevel.low = current.low;
}
}else {
//下一级NodeQueue的访问次数大于Node当前访问次数,需要在两个NodeQueue之间插入一个新的NodeQueue
unlinkNode(n);
new CacheNodeQueue(current, current.high, n, n, valueFrequency);
}
}
}
}
public V get(K key) {
CacheNode n = map.get(key);
if (n == null) {
return null;
}
moveNodeToNextLevelQueueHead(n);
return (V) n.value;
}
public void put(K key, V value) {
if (capacity == 0) {
return;
}
CacheNode cn = map.get(key);
//key已存在的情况下,更新value值,并将Node右移
if (cn != null) {
cn.value = value;
moveNodeToNextLevelQueueHead(cn);
return;
}
//cache已满的情况下,把外层链表尾部的内层链表的尾部Node移除
if (map.size() == capacity) {
CacheNodeQueue current = tail;
if(current.isSingleQueue()){
tail = current.high;
}
CacheNode node= unlinkNode(current.tail);
map.remove(node.key);
}
//插入新的Node
CacheNode n = new CacheNode(key, value);
if (this.tail == null) {
//tail为null说明此时cache中没有元素,直接把Node封装到NodeQueue里加入
CacheNodeQueue nq = new CacheNodeQueue(null, null, n, n,0);
this.tail = nq;
} else if (this.tail.frequency == 0) {
//外层链表尾部元素的访问次数是0,那么将Node加入到外层链表尾部元素的头部
// 之所以加到头部,是因为要求“如果访问次数相同的元素有多个,则移除最久访问的那个”
this.tail.addNodeToHead(n);
} else {
//外层链表尾部元素的访问次数不是0,那么实例化一个只包含此Node的NodeQueue,加入外层链表尾部
CacheNodeQueue nq = new CacheNodeQueue( null,this.tail, n, n,0);
this.tail = nq;
}
//最后把key和Node存入HashMap中
map.put(key, n);
}
}treemap
还有一种使用 jdk treemap+linklist 实现 LFU 的方案,treemap 可以实现对key(频率)的排序,其底层是一棵树,实现了map接口,刚好用于频率的排序,而Value可以使用linkedList,这样可以记录插入顺序。插入、访问、移除的时间复杂度都是O(1)
public class LFUCacheUsingTreeMap<K, V> {
Map<K, Node<K,V>> cache;
/**
* K是频率,V是按顺序插入的节点
*/
TreeMap<Integer, LinkedHashSet<Node<K,V>>> freqMap;
int capacity;
public LFUCacheUsingTreeMap(int capacity) {
this.capacity = capacity;
cache = new HashMap<>();
freqMap = new TreeMap<>();
}
public V get(K key) {
if (!cache.containsKey(key)) {
return null;
}
Node<K,V> node = cache.get(key);
//更新访问次数
refreshFreq(node);
return node.val;
}
public void put(K key, V value) {
if (capacity == 0) {
return;
}
if (cache.containsKey(key)) {
Node<K,V> node = cache.get(key);
node.val = value;
//更新访问次数
refreshFreq(node);
} else {
if (cache.size() == capacity) {
//删除频率最低的
LinkedHashSet<Node<K,V>> nodes = freqMap.get(freqMap.keySet().stream().findFirst().get());
Node node = nodes.stream().findFirst().get();
cache.remove(node.key);
deleteNodeFromFreqMap(node);
}
Node node = new Node(key, value);
cache.put(key, node);
addNodeToFreqMap(node);
}
}
private void refreshFreq(Node node) {
deleteNodeFromFreqMap(node);
node.freq++;
addNodeToFreqMap(node);
}
private void addNodeToFreqMap(Node<K,V> node) {
if (!freqMap.containsKey(node.freq)) {
freqMap.put(node.freq, new LinkedHashSet<>());
}
freqMap.get(node.freq).add(node);
}
private void deleteNodeFromFreqMap(Node<K,V> node) {
LinkedHashSet<Node<K,V>> nodes = freqMap.get(node.freq);
// 这里的消耗应该是O(1)级别的
nodes.remove(node);
if (nodes.isEmpty()) {
freqMap.remove(node.freq);
}
}
}
class Node<K,V>{
K key;
V val;
int freq;
public Node(){}
public Node(K k,V v){
this.key=k;
this.val =v;
this.freq=1;
}
}相关内容


如果你觉得这篇文章对你有所帮助,请我一杯咖啡吧~
 微信支付
微信支付 支付宝
支付宝